-
PWSCUP
-
- PWSCUP 2017 -- PWSCUP 2016 -- PWSCUP 2015 -
-
今年度のプライバシーワークショップ(PWS)活動の総括としまして,Meetupイベントを
2017年2月9日 13時~ 東京大学 本郷キャンパス 工学部6号館3階にて開催いたします.
PWS CUPの振り返りと来年度の予定,公的統計の秘匿基準,技術や法律の最新動向などの講演を予定しています.
ぜひご参加ください.
2016年10月11日に秋田で行われたPWSCUP本戦によって,最終ランキングが決定しました.
厳正な審査の結果,T-AND-Nチームが優勝となりました.おめでとうございます.
今年もPWSCUPにご参加いただいた皆様,ありがとうございました.
データの公開に賛同頂けたチームの結果データが公開されておりますので,ご参照ください.
大変お待たせいたしました.再識別フェイズの開始,及び本戦ルールを公開いたしました.
再識別フェイズのルールも変更されまして,予備戦の再識別フェイズは勝者を定めないこととなりました.詳しくは新ルール,及び最新論文をご参照ください.また,本戦参加のエントリーもお願いいたします.
予備戦:匿名化フェイズにつきまして,提出された資料を元にルールの改変が行われました. 大変申し訳ございませんが,9月7日以前に提出されたデータを論理削除いたしました.改めて新ルールに従い,ご提出をお願いいたします. それに伴い,匿名化フェイズを 9/20(火)まで延長いたしました.最新のルール,及び,指標に関する説明をご参照ください.
今月のPWS勉強会の日程が発表されました.ご興味のある方はご参加ください.
タイトル:差分プライバシーチュートリアル 講師:佐久間淳先生(筑波大学)
場所:東京大学 本郷地区キャンパス 工学部6号館3F
セミナー室AD ※計算限界(ELC)・秋の学校の発表と同じ内容です.発表スライドは英語になります.
今年度のルールが発表されました.9月1日までをルールの浸透期間と位置づけ,自由にシステムを扱える日とします.今年度のルール等についてご確認ください.
PWSCUP2016では,マスターデータと購買履歴データに対して,匿名加工と再識別を行います.
| PWS Cup参加エントリー申込期間 | 7/27(水)- 8/16(火) |
|---|---|
| 予備戦(匿名加工データ提出) | 8/25(木)- 9/13(火) |
| 予備戦(再識別データ提出) | 9/27(火)- 10/3(月) |
| 本戦(匿名加工・再識別) | 10/11 (火) 09:30 |
| 最終プレゼン,評価結果発表 | 10/12(水) 10:35 |
| No. | チーム名 | 責任者 | 組織 | コメント | データ | 写真 |
|---|---|---|---|---|---|---|
| 1 | T-AND-N | 中川裕志 | 東京大学 | きりたんぽ食べに来ました | OK | OK |
| 2 | チーム名 | 山田明 | 個人 | チームのキャッチコピー | OK | ASK |
| 3 | 狛犬 | - | - | がんばります | NG | ASK |
| 4 | Ice Sushi | 土井 洋 | 情報セキュリティ大学院大学 | 昨年は見学のみだったので、今年は手を動かして頑張ります。 | OK | ASK |
| 5 | ステテコ伊藤2 | 菊池浩明 | 明治大学総合数理学部 | 単位よりポケモンGO | OK | OK |
| 6 | がん(りゅうじ)ま | - | - | 昨年の雪辱を果たします. | NG | ASK |
| 7 | てんねんすい | 田中健二 | 所属なし | 秋田城見たい | OK | OK |
| 8 | PRIVACY HUMAN | 仲田敦 | 無し | アイム プライバシーヒューマン | NG | OK |
| 9 | カコウマシマシプライバシカラメ | - | - | ノイズ入れますか? | NG | ASK |
| 10 | チームぼっち | - | - | ぼっちでも一人でがんばるぞい! | NG | OK |
| 11 | nifigaki | 西垣正勝 | 静岡大学 | 大番狂わせを目指します! | OK | ASK |
| 12 | 一芸道 | - | - | 隠れたるより見るるはなし | NG | OK |
| 13 | 匿名戦隊アノニマーズ | - | - | データの秘密は俺たちが守る! | NG | ASK |
| 14 | Justice | - | - | 感動を、あなたに | NG | ASK |
| 15 | チーム三茶 | 池田智弘 | 無 | 初心者集団ですが、勉強のため参加します! | OK | OK |
| 16 | MDLer | 佐久間淳 | 筑波大学 | ちゃんとやります. | OK | OK |
| 17 | 鋼鉄の錬金術師 | 波多野卓磨 | 新日鉄住金ソリューションズ株式会社 | 錬金します | OK | OK |
| 18 | シライ5000 | - | - | 歯ブラシ立て欲しい! | NG | ASK |
| 19 | 付け焼刃 | - | - | 即席チームですが頑張ります^^ | NG | OK |
| 20 | ゼロから始める匿名生活 | - | - | 年齢幅が大きい学生チーム | OK | ASK |
| 21 | トシモン | - | - | The world is yours. | NG | OK |
| 22 | ブラザーフッド | 岡本 靖浩 | 個人参加 | 頑張ります | OK | OK |
| 23 | 時計仕掛けのオレンジ | - | - | プライバシ技術を磨きたいと思います! よろしくお願いします! | OK | OK |
| 24 | 先魁 | 満保 雅浩 | 金沢大学 | 修行中のかけだしですので、お手柔らかに願います | OK | OK |
| 予備戦(A) | 本戦(B) | A*0.1 | B*0.9 | 合計 | チーム名 | 組織 | 責任者 |
|---|---|---|---|---|---|---|---|
| 6 | 1 | 0.6 | 0.9 | 1.5 | T-AND-N | 東京大学 | 中川裕志 |
| 1 | 2 | 0.1 | 1.8 | 1.9 | シライ5000 | - | - |
| 5 | 3 | 0.5 | 2.7 | 3.2 | 鋼鉄の錬金術師 | 新日鉄住金ソリューションズ株式会社 | 波多野卓磨 |
| 3 | 4 | 0.3 | 3.6 | 3.9 | Justice | 電気通信大学 | 清 雄一 |
| 10 | 5 | 1 | 4.5 | 5.5 | チームぼっち | Kii株式会社 | 井口誠 |
| 4 | 6 | 0.4 | 5.4 | 5.8 | カコウマシマシプライバシカラメ | - | - |
| 2 | 8 | 0.2 | 7.2 | 7.4 | nifigaki | 静岡大学 | 西垣正勝 |
| 17 | 7 | 1.7 | 6.3 | 8.0 | ステテコ伊藤2 | 明治大学総合数理学部 | 菊池浩明 |
| 8 | 9 | 0.8 | 8.1 | 8.9 | MDLer | 筑波大学 | 佐久間淳 |
| 13 | 10 | 1.3 | 9 | 10.3 | 匿名戦隊アノニマーズ | - | - |
| 15 | 11 | 1.5 | 9.9 | 11.4 | チーム名 | - | - |
| 7 | 12 | 0.7 | 10.8 | 11.5 | 狛犬 | - | - |
| 11 | 13 | 1.1 | 11.7 | 12.8 | Ice Sushi | 情報セキュリティ大学院大学 | 土井 洋 |
| 14 | 14 | 1.4 | 12.6 | 14.0 | がん(りゅうじ)ま | - | - |
| 18 | 15 | 1.8 | 13.5 | 15.3 | 先魁 | 金沢大学 | 満保 雅浩 |
| 9 | 16 | 0.9 | 14.4 | 15.3 | ブラザーフッド | 個人参加 | 岡本 靖浩 |
| 12 | 16 | 1.2 | 14.4 | 15.6 | 時計仕掛けのオレンジ | 個人 | 松本武史 |
| 16 | 16 | 1.6 | 14.4 | 16.0 | 一芸道 | - | - |
| 19 | 16 | 1.9 | 14.4 | 16.3 | PRIVACY HUMAN | - | - |
| 20 | 16 | 2 | 14.4 | 16.4 | トシモン | - | - |
| 21 | 16 | 2.1 | 14.4 | 16.5 | チーム三茶 | 無 | 池田智弘 |
| 22 | 16 | 2.2 | 14.4 | 16.6 | 付け焼刃 | - | - |
| 23 | 16 | 2.3 | 14.4 | 16.7 | てんねんすい | 所属なし | 田中健二 |
| No. | チーム | 所属組織 | 責任者 | 合計 |
|---|---|---|---|---|
| 1 | シライ5000 | - | - | 0.03781 |
| 2 | nifigaki | 静岡大学 | 西垣正勝 | 0.04500 |
| 3 | Justice | 電気通信大学 | 清 雄一 | 0.05087 |
| 4 | カコウマシマシプライバシカラメ | - | - | 0.05644 |
| 5 | 鋼鉄の錬金術師 | 新日鉄住金ソリューションズ株式会社 | 波多野卓磨 | 0.12979 |
| 6 | T-AND-N | 東京大学 | 中川裕志 | 0.05987 |
| 7 | 狛犬 | - | - | 0.47211 |
| 8 | MDLer | 筑波大学 | 佐久間淳 | 0.59250 |
| 9 | ブラザーフッド | 個人参加 | 岡本 靖浩 | 0.49178 |
| 10 | チームぼっち | Kii株式会社 | 井口誠 | 0.58104 |
| 11 | Ice Sushi | 情報セキュリティ大学院大学 | 土井 洋 | 0.75911 |
| 12 | 時計仕掛けのオレンジ | 個人 | 松本武史 | 0.85344 |
| 13 | 匿名戦隊アノニマーズ | - | - | 0.27987 |
| 14 | がん(りゅうじ)ま | - | - | 1.00810 |
| 15 | チーム名 | - | - | 0.94618 |
| 16 | 一芸道 | - | - | 0.96610 |
| 17 | ステテコ伊藤2 | 明治大学総合数理学部 | 菊池浩明 | 1.05405 |
| 18 | 先魁 | 金沢大学 | 満保 雅浩 | 0.81969 |
| 19 | PRIVACY HUMAN | - | - | 1.91326 |
| 20 | トシモン | - | - | 2.07118 |
| 21 | チーム三茶 | 無 | 池田智弘 | 1.93032 |
| 22 | 付け焼刃 | - | - | 2.00641 |
| 23 | てんねんすい | 所属なし | 田中健二 | 2.06381 |
| No. | チーム | 所属組織 | 提出ファイル | 責任者 | 安全性 | 有用性 | 合計 |
|---|---|---|---|---|---|---|---|
| 1 | T-AND-N | 東京大学 | [M][T][P] | 中川裕志 | 0.22250 | 0.00961 | 0.23211 |
| 2 | シライ5000 | - | 非公開 | - | 0.23750 | 0.01031 | 0.24781 |
| 3 | 鋼鉄の錬金術師 | 新日鉄住金ソリューションズ株式会社 | [M][T][P] | 波多野卓磨 | 0.25500 | 0.00524 | 0.26024 |
| 4 | Justice | 電気通信大学 | [M][T][P] | 清 雄一 | 0.27500 | 0.01346 | 0.28846 |
| 5 | チームぼっち | Kii株式会社 | [M][T][P] | 井口誠 | 0.30250 | 0.01031 | 0.31281 |
| 6 | カコウマシマシプライバシカラメ | - | 非公開 | - | 0.32000 | 0.00296 | 0.32296 |
| 7 | ステテコ伊藤2 | 明治大学総合数理学部 | [M][T][P] | 菊池浩明 | 0.34750 | 0.01275 | 0.36025 |
| 8 | nifigaki | 静岡大学 | [M][T][P] | 西垣正勝 | 0.37250 | 0.04403 | 0.41653 |
| 9 | MDLer | 筑波大学 | [M][T][P] | 佐久間淳 | 0.38500 | 0.04704 | 0.43204 |
| 10 | 匿名戦隊アノニマーズ | - | 非公開 | - | 0.55000 | 0.00559 | 0.55559 |
| 11 | チーム名 | - | 非公開 | - | 0.31000 | 0.43606 | 0.74606 |
| 12 | 狛犬 | - | 非公開 | - | 0.75750 | 0.01468 | 0.77218 |
| 13 | Ice Sushi | 情報セキュリティ大学院大学 | [M][T][P] | 土井 洋 | 0.89250 | 0.04789 | 0.94039 |
| 14 | がん(りゅうじ)ま | - | 非公開 | - | 0.92750 | 0.02251 | 0.95001 |
| 15 | 先魁 | 金沢大学 | 非公開 | 満保 雅浩 | 1.00000 | 0.00000 | 1.00000 |
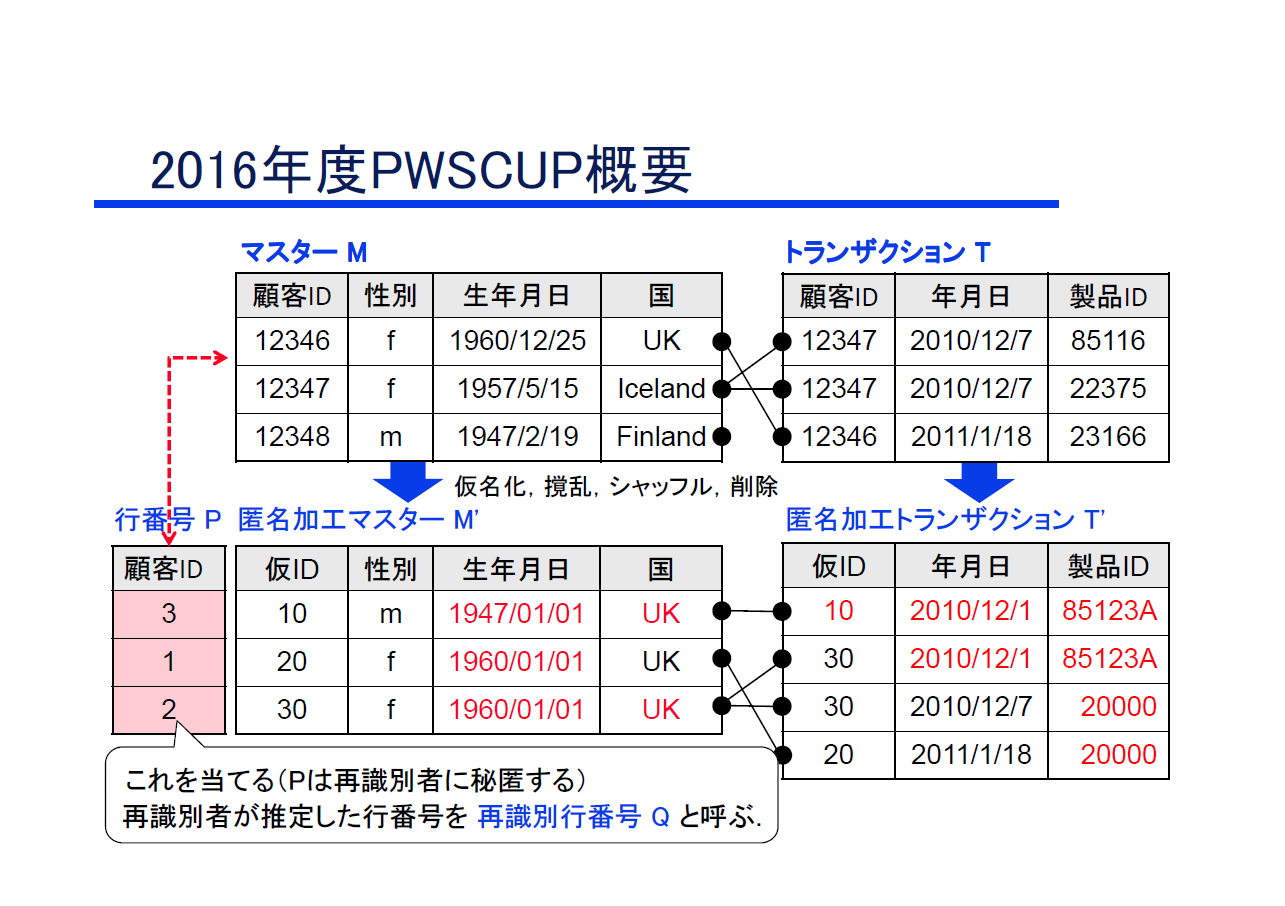
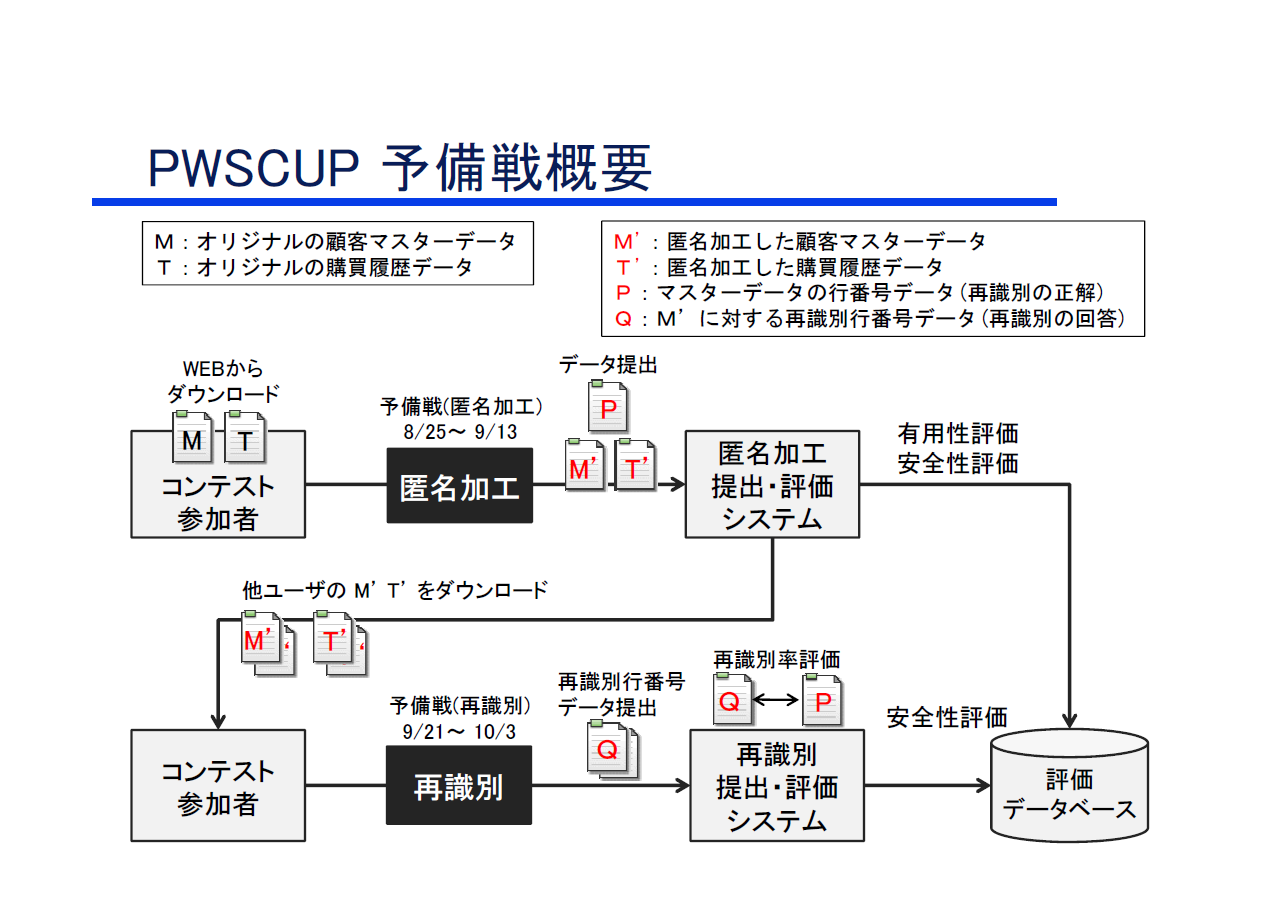
本コンテストのルール概要は以下の通り.なお,ルールは予告無く変更される場合があります..
今回の匿名加工処理,評価処理に利用されているプログラムのリストです.
サンプルプログラムと共にご確認ください.
| 指標 | 指標説明 | 作成者 | プログラム [開発言語] |
|---|---|---|---|
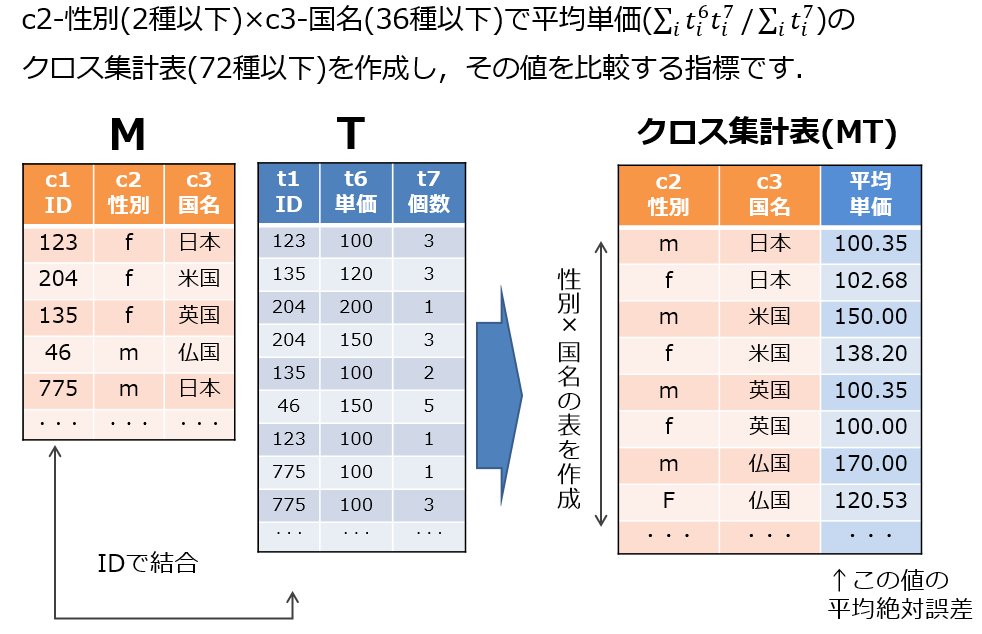
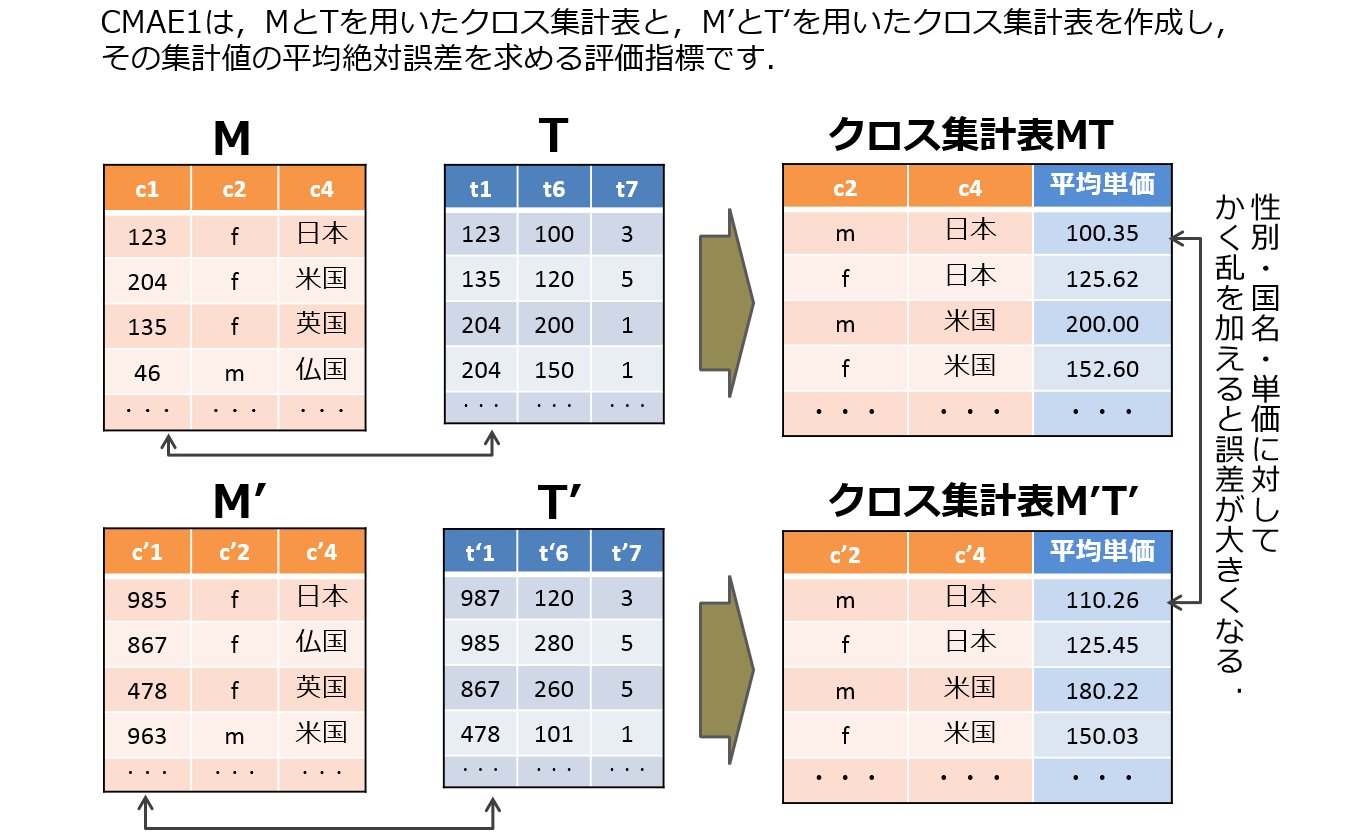
| P1U1-cmae1 | 2つのクロス集計表間のMAEを計算 (c1 vs c2, c1 は M と T,c2 は M' と T',計算.クロス集計は性別と国によりグループ化.集計値は平均単価(総購入額 / 総購入個数) | 濱田 浩気 | ut-cmae.rb [ruby] |
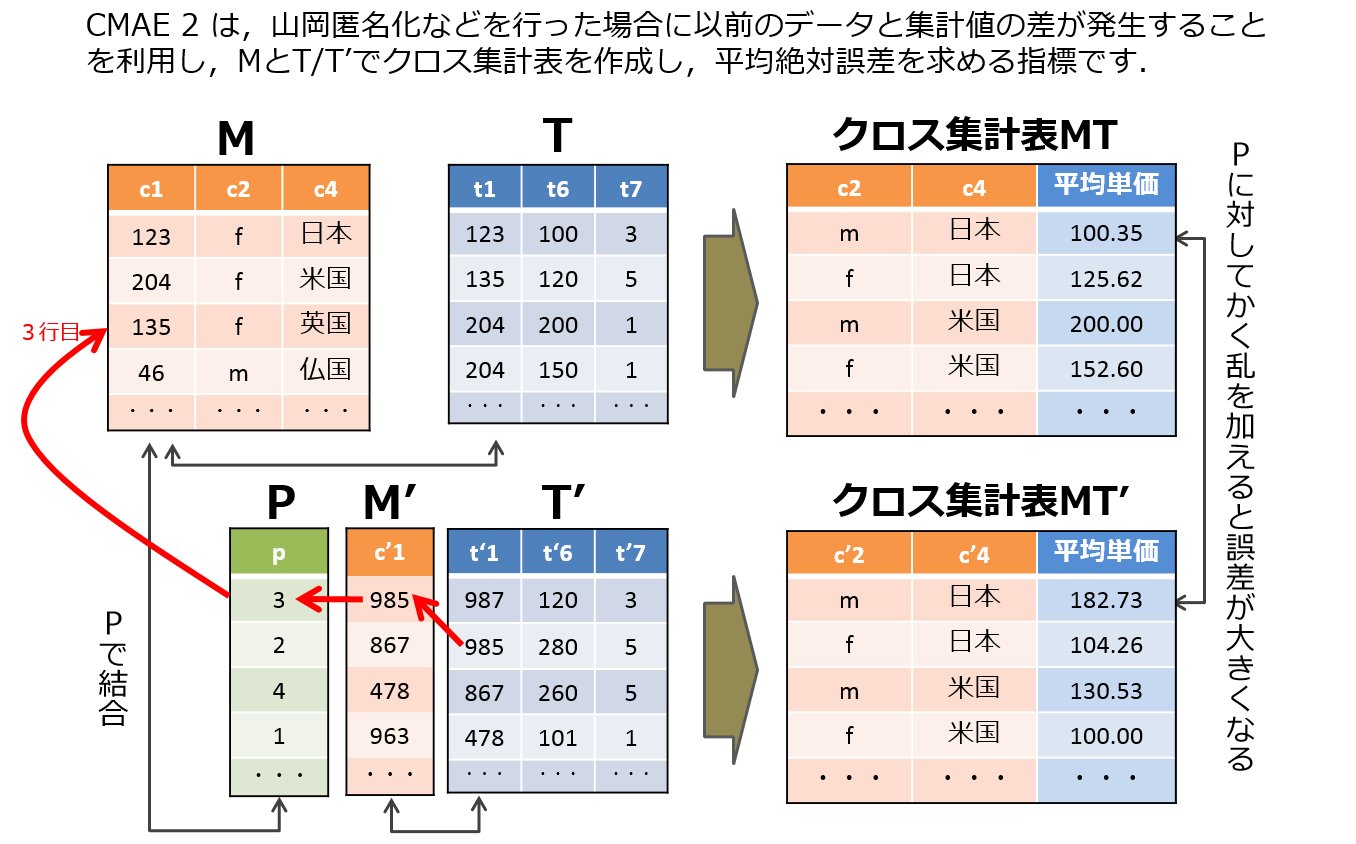
| P1U2-cmae2 | 2つのクロス集計表間のMAEを計算 (c1 vs c3, c1 は M と T,c3 は (Pにより M' の各行を対応する M の行に置き換えた表) と T' で計算されるクロス集計表)計算.クロス集計は性別と国によりグループ化.集計値は平均単価(総購入額 / 総購入個数) | 濱田 浩気 | ut-cmae.rb [ruby] |
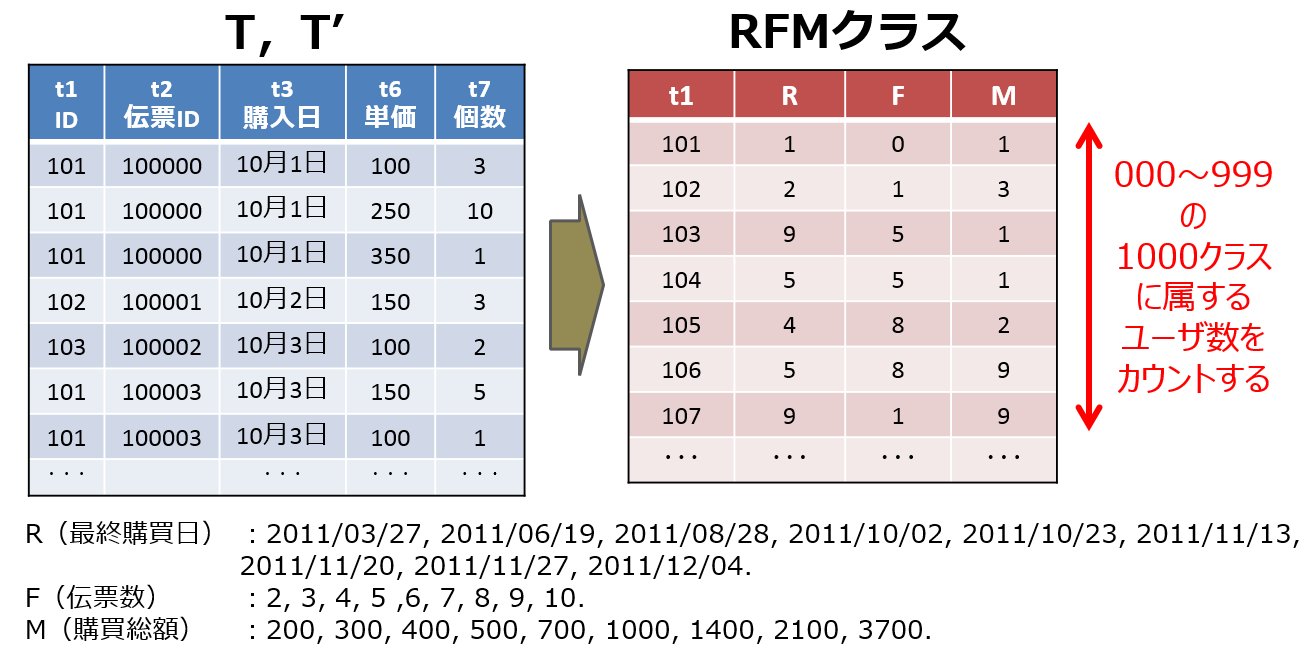
| U3-rfm | RFM分析の観点で、R, F, Mをそれぞれ10分位値を目安に10ランクに分け、計1000ランクに顧客を分類し、その度数のRMSEを出力。M'のID以外の属性や、T'の時分と製品IDは使わない。 | 山岡 裕司 | ut-rfm_t.jar [java] |
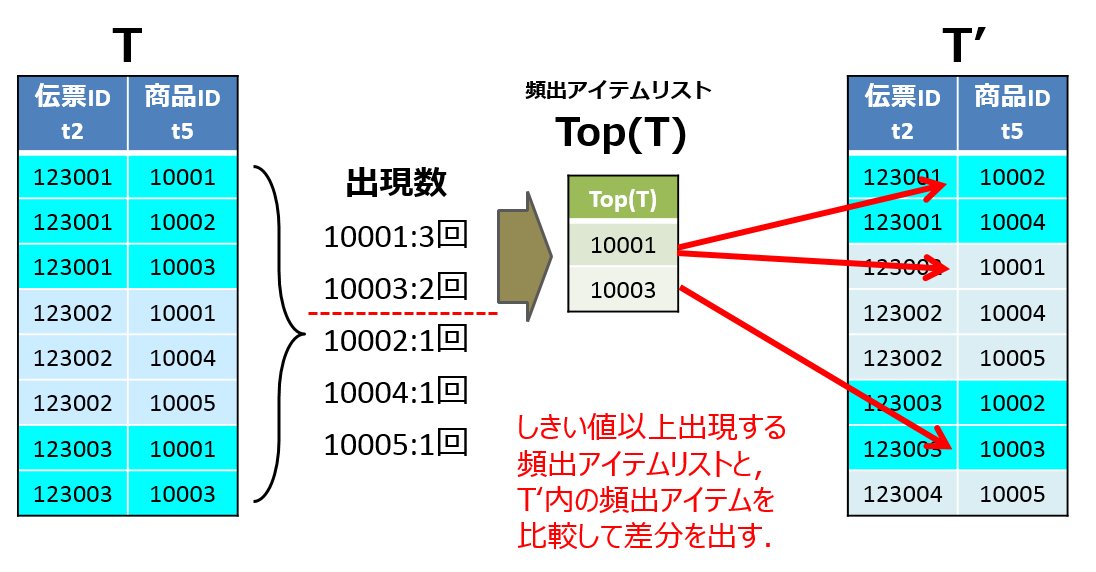
| U4-top_items | 1 - |(T の頻出アイテム集合の集合) ∩ (T' の頻出アイテム集合の集合)| / |(T の頻出アイテム集合の集合)| を計算 | 野島 良 | ut-top_items.rb [ruby] |
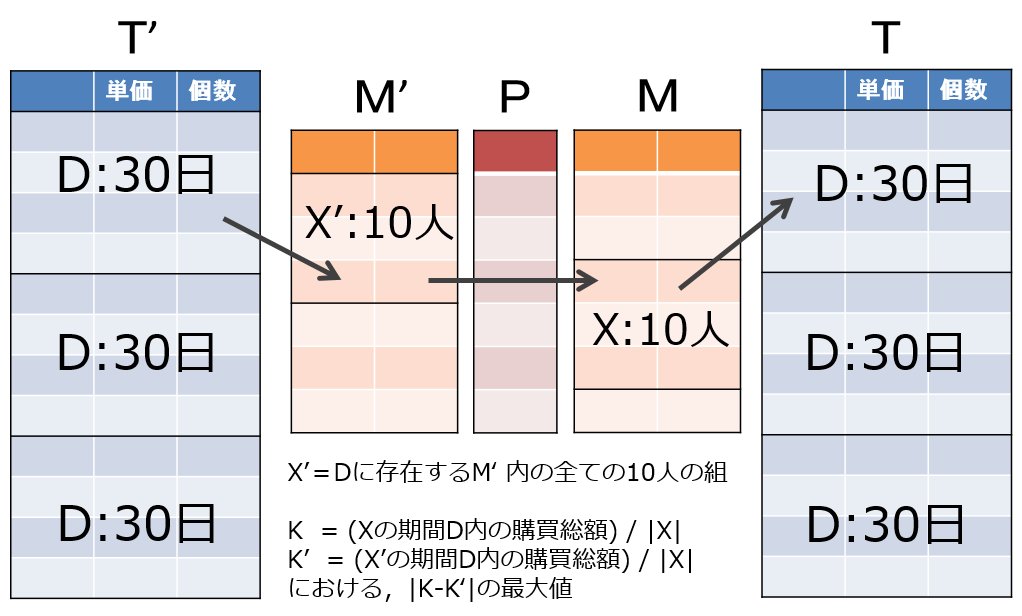
| Y-subset | 大きさ10の顧客の部分集合X / subset Mと,対応するX' / subset M'を全ての組み合わせで作成し,T上の連続した30日間Yに対し,TとT'から計算される顧客X(X')が期間Yに購入した平均購入金額をK(K')と するとき,|K-K'|/Kの最大値. | 濱田 浩気 | ut-subset.rb [ruby] |
| P1E1-birthday | 生年月日同士の距離が最小となる顧客IDに再識別 | 村上 隆夫 | re-birthday.py [python] |
| P1E2-eqi | マスターの属性(仮IDを除く)とトランザクションが完全一致するレコードを推測.なければランダム | 濱田 浩気 | re-eqi.rb [ruby] |
| E3-sort | (性別,生年月日,国)でソート | 濱田 浩気 | re-sort.rb [ruby] |
| E4-sort2 | 生年月日でソート | 濱田 浩気 | re-sort2.rb [ruby] |
| E5-recnum | レコード数マッチング(トランザクションのレコード数同士の距離が最も近い顧客に再識別) | 村上 隆夫 | re-recnum.py [python] |
| E6-eqtr | トランザクションが完全一致するレコードを推測.なければランダム | 濱田 浩気 | re-eqtr.rb [ruby] |
| E7-tnum | トランザクション数でソート | 濱田 浩気 | re-tnum.rb [ruby] |
| E8-meantime | 平均購入時刻同士の距離が最小となる顧客IDに再識別 | 村上 隆夫 | re-meantime.py [python] |
| E9-re | 常に 1, 2, 3, …, |M''| と推測 | 濱田 浩気 | re.rb [ruby] |
| E10-tnum-bi | (トランザクション数,生年月日)でソート | 濱田 浩気 | re-tnum-bi.rb [ruby] |
| E11-totprice | 総価格同士の距離が最小となる顧客IDに再識別 | 村上 隆夫 | re-totprice.py [python] |
| P1A1-ano | そのまま出力(仮ID化なし,MやTの順序置換もなし) | 濱田 浩気 | ano.rb [ruby] |
| P1A2-ano-shuffle | 特別な加工なし(仮ID化,MおよびTの順序置換は行う) | 濱田 浩気 | ano-shuffle.rb [ruby] |
| A3-ano-ya | 山岡匿名化(M を行単位でランダム置換) | 濱田 浩気 | ano-ya.rb [ruby] |
| A4-ano-tya | 教科書山岡匿名化(M の各行を上に一つずらす) | 濱田 浩気 | ano-tya.rb [ruby] |
| A5-ano-ba | 顧客IDと伝票IDはシャッフル、年月日時分の日時分は1日0:00に均一化、製品IDはMに均一化、単価と数量は有効数字1桁化、マスターはf, 1960/1/1, UKに均一化。ソースコード付き。 | 山岡 裕司 | ano-ba.jar [java] |
| A6-ano-ya | マスターデータで近そうな行(生年月日、国、性別でソートした場合の隣の行)に山岡匿名加工。 | 山岡 裕司 | ano-ya.jar [java] |
| A7-ano-swap | ランダムにkレコードずつの組(余りはk個未満の組)を作り,各組の中でMを性別,生年月日,国をそれぞれ独立にランダム置換 | 濱田 浩気 | ano-swap.rb [ruby] |
| A8-ano-swap2 | (性別,国)でソート後に上からkレコードずつの組(余りはkレコード未満の組)を作り,各組の中でMを性別,生年月日,国をそれぞれ独立にランダム置換.さらにTをランダム化 | 濱田 浩気 | ano-swap2.rb [ruby] |
| A9-ano-divt-topitem | Mの生年月日を均一化.総金額を維持したままトランザクション数を増加.さらにTをランダム化.頻出商品集合の集合に出現する商品IDに商品IDを変更 | 濱田 浩気 | ano-divt-topitem.rb [ruby] |
| A10-ano-divt | Mの生年月日を均一化.総金額を維持したままトランザクション数を増加.さらにTをランダム化 | 濱田 浩気 | ano-divt.rb [ruby] |
| Ruby用プログラム集 | Ruby用サンプルプログラム.作成者: 濱田 浩気,野島 良 |
|---|---|
| Python用プログラム集 | Python用サンプルプログラム.作成者:村上 隆夫,山口 高康 |
| Java用プログラム集 | Java用サンプルプログラム.作成者: 山岡 裕司 |
大会では,UCI Machine Learning Repository[1] の Online Retail Data Set[2] (2010年から1年分の英国のオンライン小売店での購買履歴データ,約8属性,約50万レコード,以下「購買履歴データ」「トランザクションデータ(T)」とする) を利用します.
また,このデータに対応した,顧客データベースをマスターデータ(M)として利用します.
本マスターデータは,データセットと同封してあるマスターデータ生成プログラム(datagen2.py)で生成しました.
予備戦は,全データではなく,一部を抽出したもので行う予定です.
| Transaction.csv | UCI-Online Retail Data Setをクレンジングしたデータ |
|---|---|
| Transaction-Customer100.csv | 100人の顧客データに対応した抽出データ |
| Transaction-Customer400.csv | 400人の顧客データに対応した抽出データ |
| Master.csv | マスターデータ生成プログラムで生成したデータ |
| Master-Customer100.csv | 100人の顧客データのみ抽出 |
| Master-Customer400.csv | 400人の顧客データのみ抽出 |
これらのデータセットのプロパティや提出時の注意点などは,以下の資料にまとめてあります.
| PWS CUP 2016のUCIデータおよびコンテストデータ(PDF) | 共通データセットについて |
|---|---|
| PWS CUP 2016 マスターデータの書式 Ver. 0.2(PDF) | マスターデータの書式,プロパティ |
| PWS CUP 2016 トランザクションデータの書式 Ver. 0.3 (PDF) | 購買履歴データの書式,プロパティ |
res = max(res,
min(abs(mean(x[0, num_c])),
abs(mean(x.reverse[0, num_c]))))
菊池浩明 (明治大学)
千田浩司 (NTT)
荒井ひろみ (東京大学)、伊藤伸介(中央大学)、小栗秀暢 (ニフティ)、 佐久間淳 (筑波大学)、島岡政基 (セコム)、須川賢洋 (新潟大学)、寺田雅之 (NTTドコモ)、野島良 (NICT)、濱田浩気 (NTT)、古川諒 (NEC)、南和宏 (統計数理研究所)、村上隆夫 (産業技術総合研究所)、山岡裕司 (富士通研)、山口高康 (NTTドコモ)、吉浦裕 (電気通信大学)、渡辺知恵美(筑波大学)