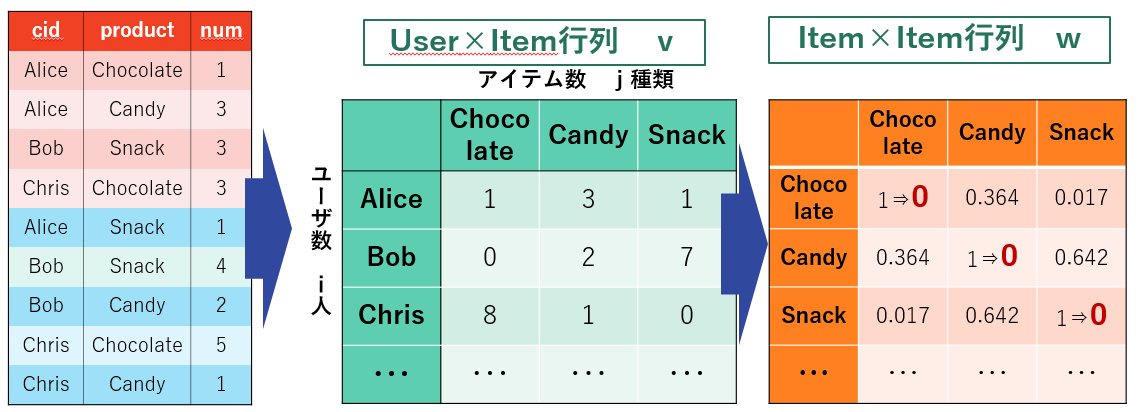
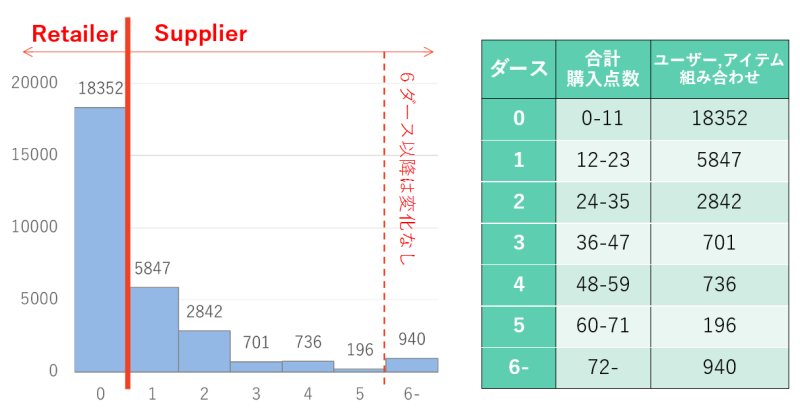
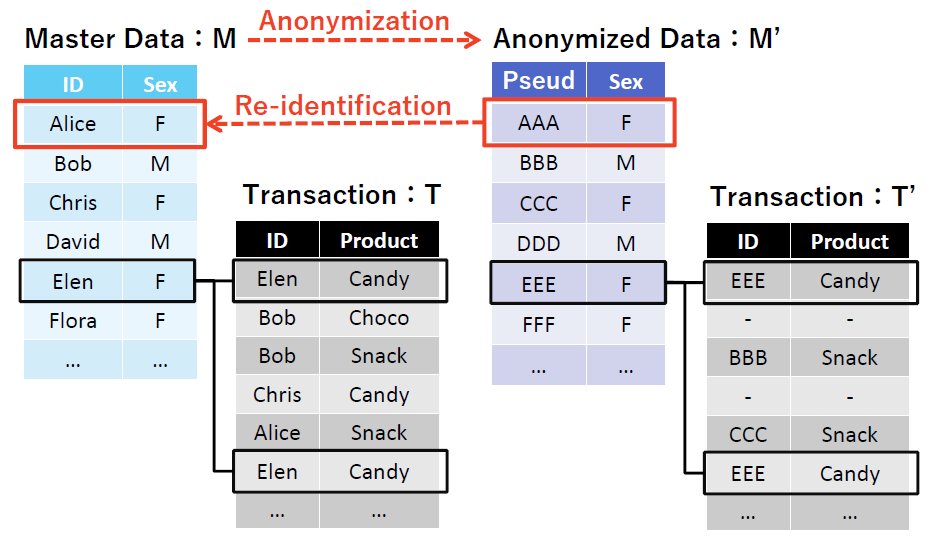
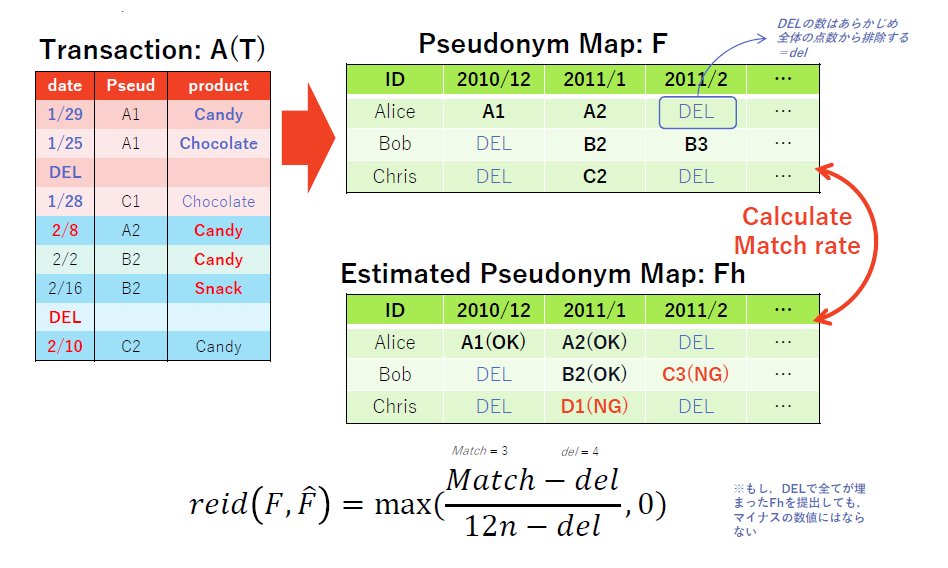
今大会で利用するデータフォーマットについてまとめます.
※本WEBサイトは概要のみ記しています.正確な定義は,ルール論文,ルールブックを参照ください.
■ PWSCUP 2017 ルール論文 ■ PWSCUP 2017 競技ルール ■ 競技データ&プログラム 以下のオリジナルデータ,サンプルデータは一括でダウンロードできます.
データ説明()で括られたファイルは,サンプルデータ内に含まれている対応するファイル名です.
M ,
T は,昨年度のファイルフォーマットと同じものを利用しているため,各データ形式の詳細は資料をご確認ください.
※参考 PWS CUP 2016 トランザクションデータの書式 今年度は,
M は加工対象ではありません.
T のみが匿名加工対象です.
M : オリジナルの顧客マスターデータ( M.csv )
| M | 通称 | 区分 | 書式概要 |
|---|
| c・,1 | 顧客ID | 識別子 | 50byte以下の任意の英数文字列 |
|---|
| c・,2 | 性別 | 属性 | 「f」か「m」 |
|---|
| c・,3 | 年代 | 属性 | 1930/1/1 ~ 1980/1/1 |
|---|
| c・,4 | 国 | 属性 | United Kingdom,France,Germany,Others |
|---|
T : オリジナルの購買履歴データ ( T_sample.csv )
| T | 通称 | 区分 | 書式概要 |
|---|
| t・,1 | 顧客ID | 識別子 | 任意の英数文字列 |
|---|
| t・,2 | 伝票ID | 識別子 | 消去済み |
|---|
| t・,3 | 購入日時 | 日付 | 2010,2011年のYYYY/MM/DD形式 |
|---|
| t・,4 | 購入時間 | 時間 | hh:mm 形式 |
|---|
| t・,5 | 商品ID | 属性 | 9文字以下の任意の大文字英数文字列 |
|---|
| t・,6 | 単価 | 数値 | 整数部5桁以下、小数部2桁以下の正小数 |
|---|
| t・,7 | 購入数 | 数値 | 6桁以下の自然数 |
|---|
例1: T のサンプル
A(T) : T を加工制限の範囲内で匿名加工したデータ
S : A(T) の提出後,削除行を排除し,行番号をかく乱したデータ
F : T と A(T) の関係から作成された仮名表
A(T) の加工制限
以下の加工制限の範囲内で作成したA(T)をシステムに提出してください.
※本WEBページは概要説明です.正式な定義はルール論文とルールブックを参照ください.
1 ) 匿名加工履歴データ
A(T) の行の順序は,購買履歴データ
T と同一とする.
2 )
T に存在しない行の追加は認めない.
3 )
T に含まれる行を削除する場合は,当該行を [DEL,,,,,,
] と記載する.すなわち,列数は変更しない.
以下,削除した行を'DEL行'とする.
例2:例1の T の2行目を削除する場合
4 )
A(T) に含まれるDEL行は,全行数の50%以上になってはいけない.
5 )
A(T) に含まれる属性の1列目は元情報の識別子であるため,元の識別子とは異なる仮名を付与すること.
6 )
A(T) の仮名は期間内では矛盾のない様に割当てる.同じ月内において仮名を変更してはならない.
例3:例1の T に仮名を付与したが,4行目に異なる仮名を割り当て,エラーになる例
7 ) 月ごとに仮名は必ずしも変更しなくてよい.月をまたいで同一人物に同じ仮名をつけても良い.
8 ) 'DEL' という仮名は禁じる.
9 ) 購買履歴データ T に含まれない商品ID(
t⋅,5 )を含む匿名加工履歴データ
A(T) を加工すること.
単価
t⋅,6 ,数量
t⋅,7 はこの制約はない.
10 ) 日付
t・,3 属性は,本来分割されたデータであることから,月をまたいだ加工を禁じる.
例4:例1の T の日付を加工したが,月をまたいでエラーになる例
11) 生成した
A(T) は,'AT_*****.csv' という名前のファイル名として,システムに提出すること.
上記の加工制限を逸脱していない場合,有用性・安全性評価に進むことができる.
S と F のフォーマット
システムに提出された
A(T) は,有用性,安全性の評価後に,
S と
F に加工して,他ユーザに秘匿して管理される.
S は,
A(T) からDEL行を排除し,行番号をかく乱したものである.
この処理は
A(T) の提出後にシステム内で自動に行われ,再識別フェイズ以降,他参加者に公開される.
例5:例2の A(T) に仮名を付与した後,行番号をかく乱された例
また,システム内では,
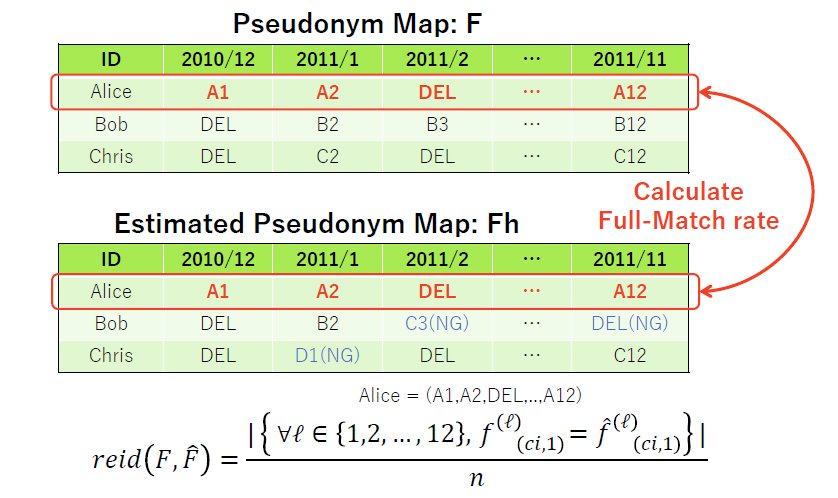
T A(T) ,仮名表
F を生成する.
仮名表は,
元の識別子,2010年12月の仮名,2011年1月の仮名,2011年2月の仮名,...,2011年11月の仮名
という形式で表す.
再識別フェイズは,この仮名表
F を推定して作成した
^F を生成し,提出する.
F と
^F は同じフォーマットであるため,以下を参考に生成すること.
例6:仮名表 F の例
この表は以下のようなテーブルであると考えると理解しやすい.
特に,開始月が2010年12月であることに注意すること.
例7:例6の仮名表 F をテーブル化したもの
| 識別子 | 2010/12 | 2011/1 | 2011/2 | 2011/3 | 2011/4 | 2011/5 | 2011/6 | 2011/7 | 2011/8 | 2011/9 | 2011/10 | 2011/11 |
|---|
| 12431 | ABCDE | DEL | DEL | DEL | DEL | ABCDE | CDEFG | CDEFG | CDEFG | CDEFG | CDEFG | CDEFG |
| 15100 | VWXYZ | VWXYZ | VWXYZ | DEL | XYZAB | DEL | DEL | DEL | DEL | VWXYZ | VWXYZ | DEL |
| 16211 | DEL | HIJKL | DEL | DEL | DEL | HIJKL | DEL | DEL | DEL | DEL | DEL | DEL |
例7の表では,顧客12431氏は,2010年12月から2011年5月までABCDEという仮名に変換され,2011年6月からはCDEFGという仮名に変更された.2011年1月から2011年4月までは何も購入していないため仮名は存在せず,DELと表す.
また,顧客15100氏は,2011年4月にXYZABという仮名に変換されたが,その後はその仮名は使用していない.
このような加工も提出データとして認める.